作為一個軟件開發(fā)者,你一定會對網(wǎng)絡(luò)應(yīng)用如何工作有一個完整的層次化的認知,同樣這里也包括這些應(yīng)用所用到的技術(shù):像瀏覽器,HTTP,HTML,網(wǎng)絡(luò)服務(wù)器,需求處理等等。
本文將更深入的研究當你輸入一個網(wǎng)址的時候,后臺到底發(fā)生了一件件什么樣的
1. 首先嘛,你得在瀏覽器里輸入要網(wǎng)址:

2. 瀏覽器查找域名的IP地址:

導(dǎo)航的第一步是通過訪問的域名找出其IP地址。DNS查找過程如下:
- 瀏覽器緩存
瀏覽器會緩存DNS記錄一段時間。 有趣的是,操作系統(tǒng)沒有告訴瀏覽器儲存DNS記錄的時間,這樣不同瀏覽器會儲存?zhèn)€自固定的一個時間(2分鐘到30分鐘不等)。 - 系統(tǒng)緩存
如果在瀏覽器緩存里沒有找到需要的記錄,瀏覽器會做一個系統(tǒng)調(diào)用(windows里是gethostbyname)。這樣便可獲得系統(tǒng)緩存中的記錄。 - 路由器緩存
接著,前面的查詢請求發(fā)向路由器,它一般會有自己的DNS緩存。 - ISP DNS 緩存
接下來要check的就是ISP緩存DNS的服務(wù)器。在這一般都能找到相應(yīng)的緩存記錄。 - 遞歸搜索
你的ISP的DNS服務(wù)器從跟域名服務(wù)器開始進行遞歸搜索,從.com頂級域名服務(wù)器到Facebook的域名服務(wù)器。一般DNS服務(wù)器的緩存中會有.com域名服務(wù)器中的域名,所以到頂級服務(wù)器的匹配過程不是那么必要了。
DNS遞歸查找如下圖所示:
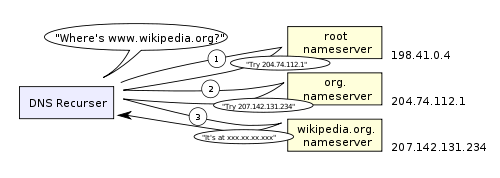
DNS有一點令人擔憂,這就是像wikipedia.org 或者 facebook.com這樣的整個域名看上去只是對應(yīng)一個單獨的IP地址。還好,有幾種方法可以消除這個瓶頸:
- 循環(huán) DNS 是DNS查找時返回多個IP時的解決方案。舉例來說,F(xiàn)acebook.com實際上就對應(yīng)了四個IP地址。
- 負載平衡器 是以一個特定IP地址進行偵聽并將網(wǎng)絡(luò)請求轉(zhuǎn)發(fā)到集群服務(wù)器上的硬件設(shè)備。 一些大型的站點一般都會使用這種昂貴的高性能負載平衡器。
- 地理 DNS 根據(jù)用戶所處的地理位置,通過把域名映射到多個不同的IP地址提高可擴展性。這樣不同的服務(wù)器不能夠更新同步狀態(tài),但映射靜態(tài)內(nèi)容的話非常好。
- Anycast 是一個IP地址映射多個物理主機的路由技術(shù)。 美中不足,Anycast與TCP協(xié)議適應(yīng)的不是很好,所以很少應(yīng)用在那些方案中。
大多數(shù)DNS服務(wù)器使用Anycast來獲得高效低延遲的DNS查找。
3. 瀏覽器給web服務(wù)器發(fā)送一個HTTP請求:
因為像Facebook主頁這樣的動態(tài)頁面,打開后在瀏覽器緩存中很快甚至馬上就會過期,毫無疑問他們不能從中讀取。
所以,瀏覽器將把一下請求發(fā)送到Facebook所在的服務(wù)器:
GET http://facebook.com/ HTTP/1.1
Accept: application/x-ms-application, image/jpg, application/xaml+xml, [...]
User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; [...]
Accept-Encoding: gzip, deflate
Connection: Keep-Alive
Host: facebook.com
Cookie: datr=1265876274-[...]; locale=en_US; lsd=WW[...]; c_user=2101[...]
GET 這個請求定義了要讀取的URL: “http://facebook.com/”。 瀏覽器自身定義 (User-Agent 頭), 和它希望接受什么類型的相應(yīng) (Accept and Accept-Encoding 頭). Connection頭要求服務(wù)器為了后邊的請求不要關(guān)閉TCP連接。
請求中也包含瀏覽器存儲的該域名的cookies。可能你已經(jīng)知道,在不同頁面請求當中,cookies是與跟蹤一個網(wǎng)站狀態(tài)相匹配的鍵值。這樣cookies會存儲登錄用戶名,服務(wù)器分配的密碼和一些用戶設(shè)置等。Cookies會以文本文檔形式存儲在客戶機里,每次請求時發(fā)送給服務(wù)器。
用來看原始HTTP請求及其相應(yīng)的工具很多。作者比較喜歡使用fiddler,當然也有像FireBug這樣其他的工具。這些軟件在網(wǎng)站優(yōu)化時會幫上很大忙。
除了獲取請求,還有一種是發(fā)送請求,它常在提交表單用到。發(fā)送請求通過URL傳遞其參數(shù)(e.g.: http://robozzle.com/puzzle.aspx?id=85)。發(fā)送請求在請求正文頭之后發(fā)送其參數(shù)。
像“http://facebook.com/”中的斜杠是至關(guān)重要的。這種情況下,瀏覽器能安全的添加斜杠。而像“http: //example.com/folderOrFile”這樣的地址,因為瀏覽器不清楚folderOrFile到底是文件夾還是文件,所以不能自動添加 斜杠。這時,瀏覽器就不加斜杠直接訪問地址,服務(wù)器會響應(yīng)一個重定向,結(jié)果造成一次不必要的握手。
4. facebook服務(wù)的永久重定向響應(yīng)
圖中所示為Facebook服務(wù)器發(fā)回給瀏覽器的響應(yīng):
HTTP/1.1 301 Moved Permanently
Cache-Control: private, no-store, no-cache, must-revalidate, post-check=0,
pre-check=0
Expires: Sat, 01 Jan 2000 00:00:00 GMT
Location: http://www.facebook.com/
P3P: CP=”DSP LAW”
Pragma: no-cache
Set-Cookie: made_write_conn=deleted; expires=Thu, 12-Feb-2009 05:09:50 GMT;
path=/; domain=.facebook.com; httponly
Content-Type: text/html; charset=utf-8
X-Cnection: close
Date: Fri, 12 Feb 2010 05:09:51 GMT
Content-Length: 0
服務(wù)器給瀏覽器響應(yīng)一個301永久重定向響應(yīng),這樣瀏覽器就會訪問“http://www.facebook.com/” 而非“http://facebook.com/”。
為什么服務(wù)器一定要重定向而不是直接發(fā)會用戶想看的網(wǎng)頁內(nèi)容呢?這個問題有好多有意思的答案。
其中一個原因跟搜索引擎排名有 關(guān)。你看,如果一個頁面有兩個地址,就像http://www.igoro.com/ 和http://igoro.com/,搜索引擎會認為它們是兩個網(wǎng)站,結(jié)果造成每一個的搜索鏈接都減少從而降低排名。而搜索引擎知道301永久重定向是 什么意思,這樣就會把訪問帶www的和不帶www的地址歸到同一個網(wǎng)站排名下。
還有一個是用不同的地址會造成緩存友好性變差。當一個頁面有好幾個名字時,它可能會在緩存里出現(xiàn)好幾次。
5. 瀏覽器跟蹤重定向地址
現(xiàn)在,瀏覽器知道了 “http://www.facebook.com/”才是要訪問的正確地址,所以它會發(fā)送另一個獲取請求:
GET http://www.facebook.com/ HTTP/1.1
Accept: application/x-ms-application, image/jpg, application/xaml+xml, [...]
Accept-Language: en-US
User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; [...]
Accept-Encoding: gzip, deflate
Connection: Keep-Alive
Cookie: lsd=XW[...]; c_user=21[...]; x-referer=[...]
Host: www.facebook.com
頭信息以之前請求中的意義相同。
6. 服務(wù)器“處理”請求

服務(wù)器接收到獲取請求,然后處理并返回一個響應(yīng)。
這表面上看起來是一個順向的任務(wù),但其實這中間發(fā)生了很多有意思的東西- 就像作者博客這樣簡單的網(wǎng)站,何況像facebook那樣訪問量大的網(wǎng)站呢!
* Web 服務(wù)器軟件
web服務(wù)器軟件(像IIS和阿帕奇)接收到HTTP請求,然后確定執(zhí)行什么請求處理來處理它。請求處理就是一個能夠讀懂請求并且能生成HTML來進行響應(yīng)的程序(像ASP.NET,PHP,RUBY…)。
舉個最簡單的例子,需求處理可以以映射網(wǎng)站地址結(jié)構(gòu)的文件層次存儲。像http://example.com/folder1/page1.aspx這個地址會映射/httpdocs/folder1/page1.aspx這個文件。web服務(wù)器軟件可以設(shè)置成為地址人工的對應(yīng)請求處理,這樣 page1.aspx的發(fā)布地址就可以是http://example.com/folder1/page1。
* 請求處理
請求處理閱讀請求及它的參數(shù)和cookies。它會讀取也可能更新一些數(shù)據(jù),并講數(shù)據(jù)存儲在服務(wù)器上。然后,需求處理會生成一個HTML響應(yīng)。
所有動態(tài)網(wǎng)站都面臨一個有意思的難點 -如何存儲數(shù)據(jù)。小網(wǎng)站一半都會有一個SQL數(shù)據(jù)庫來存儲數(shù)據(jù),存儲大量數(shù)據(jù)和/或訪問量大的網(wǎng)站不得不找一些辦法把數(shù)據(jù)庫分配到多臺機器上。解決方案 有:sharding (基于主鍵值講數(shù)據(jù)表分散到多個數(shù)據(jù)庫中),復(fù)制,利用弱語義一致性的簡化數(shù)據(jù)庫。
委托工作給批處理是一個廉價保持數(shù)據(jù)更新的技術(shù)。舉例來講,F(xiàn)ackbook得及時更新新聞feed,但數(shù)據(jù)支持下的“你可能認識的人”功能只需要每晚更新 (作者猜測是這樣的,改功能如何完善不得而知)。批處理作業(yè)更新會導(dǎo)致一些不太重要的數(shù)據(jù)陳舊,但能使數(shù)據(jù)更新耕作更快更簡潔。
隨機推薦
- 網(wǎng)頁理論 | 2016-07-25
- 網(wǎng)頁理論 | 2010-01-06
- 網(wǎng)頁理論 | 2006-03-23
- 網(wǎng)頁理論 | 2006-03-14
- 網(wǎng)頁理論 | 2005-05-26
- 網(wǎng)頁理論 | 2006-03-21